|


 Curently online :
51 Curently online :
51 |
|
 Total visitors :
7667943 Total visitors :
7667943 |
|
|
SequencErr: measuring and suppressing sequencer errors in next-generation sequencing data
Tuesday, 2021/07/06 | 06:21:58
|
|
Eric M Davis, Yu Sun, Yanling Liu, Pandurang Kolekar, Ying Shao, Karol Szlachta, Heather L Mulder, Dongren Ren, Stephen V Rice, Zhaoming Wang, Joy Nakitandwe, Alexander M Gout, Bridget Shaner, Salina Hall, Leslie L Robison, Stanley Pounds, Jeffery M Klco, John Easton, Xiaotu Ma.
Genome Biol.; 2021 Jan 25; 22(1):37. doi: 10.1186/s13059-020-02254-2.
Background: There is currently no method to precisely measure the errors that occur in the sequencing instrument/sequencer, which is critical for next-generation sequencing applications aimed at discovering the genetic makeup of heterogeneous cellular populations.
Results: We propose a novel computational method, SequencErr, to address this challenge by measuring the base correspondence between overlapping regions in forward and reverse reads. An analysis of 3777 public datasets from 75 research institutions in 18 countries revealed the sequencer error rate to be ~ 10 per million (pm) and 1.4% of sequencers and 2.7% of flow cells have error rates > 100 pm. At the flow cell level, error rates are elevated in the bottom surfaces and > 90% of HiSeq and NovaSeq flow cells have at least one outlier error-prone tile. By sequencing a common DNA library on different sequencers, we demonstrate that sequencers with high error rates have reduced overall sequencing accuracy, and removal of outlier error-prone tiles improves sequencing accuracy. We demonstrate that SequencErr can reveal novel insights relative to the popular quality control method FastQC and achieve a 10-fold lower error rate than popular error correction methods including Lighter and Musket.
Conclusions: Our study reveals novel insights into the nature of DNA sequencing errors incurred on DNA sequencers. Our method can be used to assess, calibrate, and monitor sequencer accuracy, and to computationally suppress sequencer errors in existing datasets.
See: https://pubmed.ncbi.nlm.nih.gov/33487172/
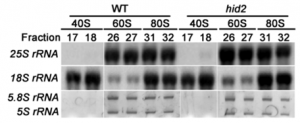
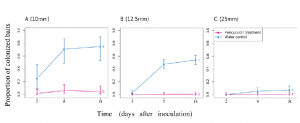
Figure 1: Measuring sequencer error rates. a, b Reference DNA method, where large amounts of reference DNA are needed. This can be achieved by starting from a small amounts of DNA/cells (to minimize inter-molecule/cell genetic heterogeneity) followed a by a large number of PCR cycles and sequencing. Alternatively, we can start from b large amounts of starting DNA/cells followed by a small number of PCR cycles (to minimize PCR errors) and sequencing. In both approaches, mutations/PCR errors (red dots) before sequencing can confound the sequencer error rate estimate (red triangles). c We interrogate the sequencer errors by focusing on discordant bases between forward and reverse reads of the same DNA segment within the overlapping regions. Such mismatches must have happened in the sequencer. d Public datasets produced by HiSeq, NextSeq, and NovaSeq as of December 2019. Datasets without proper read names, with very small sizes, or with very short reads (so that overlap is minimal) are not suitable for our analysis (see the “Methods” section). HiSeq has the most suitable datasets and we downloaded and analyzed ~ 50% of these. e–g Tile-level error rate across representative sequencers for e HiSeq, f NextSeq, and g NovaSeq. In each panel, a “good” sequencer (top) is illustrated with a “problematic” sequencer (bottom), where sequencer identifiers are indicated on the right. h Comparison of overall error rate (oER) and sequencer error rate (with or without computational error suppression) measurements on a common DNA library (generated by PCR enzymes Kapa and Q5) sequenced by two sequencing providers (St. Jude Children’s Research Hospital Computational Biology Genomics Laboratory (SJ) and HudsonAlpha Institute of Biotechnology (HAIB)), with two different NovaSeq sequencers. Tile arrangements are determined according to vendor documentation (see the “Methods” section). Tile-level error rates are capped at 200 per million for visualization purposes. ***Significant Wilcoxon rank-sum test (two-sided) P value (< 0.01). n.s, not significant (P > 0.01) |
|
|
|
[ Other News ]___________________________________________________
|
(132).png "SequencErr: measuring and suppressing sequencer errors in next-generation sequencing data")