|
M. Timothy Rabanus‑Wallace, Nils Stein.
Theoretical and Applied Genetics October 2023; vol. 106:208
Key message
We demonstrate how an algorithm that uses cheap genetic marker data can ensure the taxonomic assignments of genebank samples are complete, intuitive, and consistent—which enhances their value.
Abstract
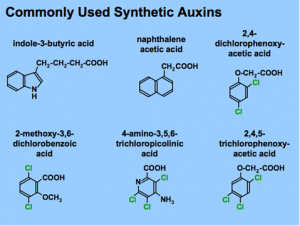
To maximise the benefit of genebank resources, accurate and complete taxonomic assignments are imperative. The rise of genebank genomics allows genetic methods to be used to ensure this, but these need to be largely automated since the number of samples dealt with is too great for efficient manual recategorisation, however no clearly optimal method has yet arisen. A recent landmark genebank genomic study sequenced over 10,000 genebank accessions of peppers (Capsicum spp.), a species of great commercial, cultural, and scientific importance, which suffers from much taxonomic ambiguity. Similar datasets will, in coming decades, be produced for hundreds of plant taxa, affording a perfect opportunity to develop automated taxonomic correction methods in advance of the incipient genebank genomics explosion, alongside providing insights into pepper taxonomy in general. We present a marker-based taxonomic assignment approach that combines ideas from several standard classification algorithms, resulting in a highly flexible and customisable classifier suitable to impose intuitive assignments, even in highly reticulated species groups with complex population structures and evolutionary histories. Our classifier performs favourably compared with key alternative methods. Possible sensible alterations to pepper taxonomy based on the results are proposed for discussion by the relevant communities.
See https://link.springer.com/article/10.1007/s00122-023-04441-8
(117).png "Accurate, automated taxonomic assignment of genebank accessions: a new method demonstrated using high throughput marker data from 10,000 Capsicum spp. accessions")
Figure 1: t-SNE plots representing the relationships among the G2P-Sol pepper accessions used in the study (trimmed dataset—see “Methods”) and their classifications under different schemes, as represented with t-SNE plots (calculated from IBS distances, perplexity = 30). Markers labelled with Roman numerals are referred to in the main text. For k-nearest-neighbours, van Bemmelen van der Plaat (2021) recommend k = 3 in general. We use k=6, which we judged to give the best result possible for this dataset (see Supplementary Materials for a range of values). At k=7, C. eximium (marker ix) are reassigned as C. chacoense. The unassignment cutoff r is set to 4/6. Parameters for the kernel-based method are λ=320�=320, d=0.2�=0.2, r=0.66�=0.66, k=∞λ=320, d=0.2, r=0.66, k=∞
|
[ Other News ]___________________________________________________
|


 Curently online :
41
Curently online :
41 Total visitors :
7651715
Total visitors :
7651715